时隔一年,名龙堂造&Intel粉

从探索人类前沿科技的超算,到普通人掏出手机就能体验的智能推荐算法,每套以至高算力为目标的集群系统都需要解决一个算力之外的关键问题——网络。
是的,分布式技术用“把大问题拆成小问题”的方法为人们提供了一条以量变实现质变的可行路径。但分开进行的海量计算总还是需要一个汇总结果并继续推进计算的过程。而这一过程对网络的带宽、延迟和丢包率都提出了极高要求。以目前流行的深度学习算法为例,0.1%的丢包率就会带来50%的集群效率降低。
在构建算力集群时,用户通常有两种选择:一种是没有丢包困扰成本较高且生态封闭的Infiniband网络,另一种则是性价比更高但需要花费精力降低延迟和丢包率的以太网技术。而对于更看重效率效果的互联网行业来说,答案只有一个——这些特性全都要!
哔哩哔哩基于业务发展需求
需要建设一张高性能计算网络
哔哩哔哩,简称“B站”,一个有用有趣的综合性视频社区,被用户们亲切地称为“百科全书式的网站、没有围墙的图书馆,成长道路上的加油站,创作者的舞台”。截止2024年第二季度,B站日均活跃用户达1.02亿。围绕用户、创作者和内容,B站构建了一个源源不断产生优质内容的生态系统。基于AI的“千人千面”内容推荐算法,B站能把好内容推荐给感兴趣的用户,进入内容量与用户活跃度双向激励的正循环。而要在海量内容、庞大访问量、亿级用户的背景下,完成精准的内容推荐,B站需要一套高性能网络为用户提供服务。
面对实时更新的内容和快速变化的用户关注点,B站的AI算力集群要尽可能快地完成“样本导入——训练——模型导出——推理”的完整业务流程,缩短AI技术与业务应用之间的距离。需求看似稀松平常,但这个“快”字却对应了多维度的底层技术挑战。
其一,拉通整个AI业务流程,实现业务整体的快。
“样本导入——训练——模型导出——推理”等各个功能的子集群需置于同一张网络之中,形成一张庞大的算力网络;尽可能让数据和模型更快传输,让不同功能形成整体,实现业务层面的快。
其二,在关键的训练集群内部,网络延迟要足够低。
大模型训练过程对网络延迟非常敏感,高延迟不仅会影响GPU节点之间的同步性和一致性,让GPU花费更多时钟周期来等待计算结果和参数的同步,更会影响整个集群的可扩展性和算力利用率。
其三,在“算网一体”的宏观趋势之下,算力方案与网络架构应保持高度匹配。
算与网就如同车和路,二者的高度匹配才能大幅提升系统整体运行效率,并为后续的运维管理和升级扩容带来更大提升空间。
一面是业务层面的严苛需求,另一面则是缺货、禁售等外部因素所带来的巨大不确定风险;经过对网络、计算、经验和供货等诸多因素的考察比对之后,B站选择牵手华为,共同构建新一代AI算力集群。
用以太网统一承载
让AI算网一体高度统一融合
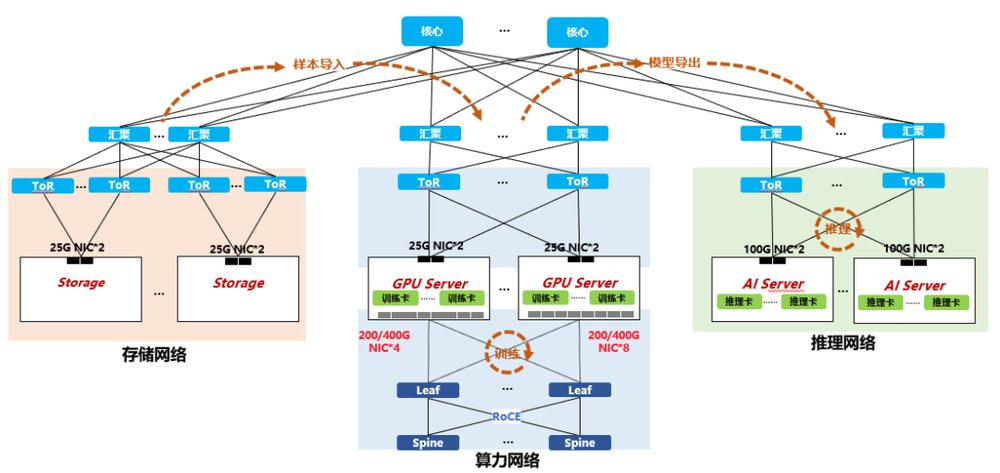
图1.多网融合网络架构图
B站网络技术团队与华为联合设计了基于以太网的“一张网”算力集群建设方案。该方案通过华为CE16800系列核心框式交换机,能够将海量样本数据的存储集群、包含海量GPU计算节点的训练集群和负责业务应用的推理集群整合成一张庞大的业务网络,为每个业务功能提供足够的数据带宽。使用一张网联接数据和业务、训练和推理,打通功能之间的烟囱壁垒,提升业务整体运行效率。相对于私有化的Infiniband网络,使用统一且开放的以太网通讯协议也有助于降低系统总体建设成本,并保持“一张网”内部的架构统一、协议统一,继而降低建设、运维的成本及难度。
在网络架构确定之后,接下来是选择AI算力网络的硬件选型和组网方案。在组网硬件选型上,华为提供多种硬件组网方式,典型的有盒盒组网方案,盒框组网方案,框框组网方案。通过双方多次技术交流,综合B站机房现场环境条件、硬件成本等多方面考虑,B站选择盒盒组网的方案,如下图所示,构建的是一张千卡规模的AI算力集群。
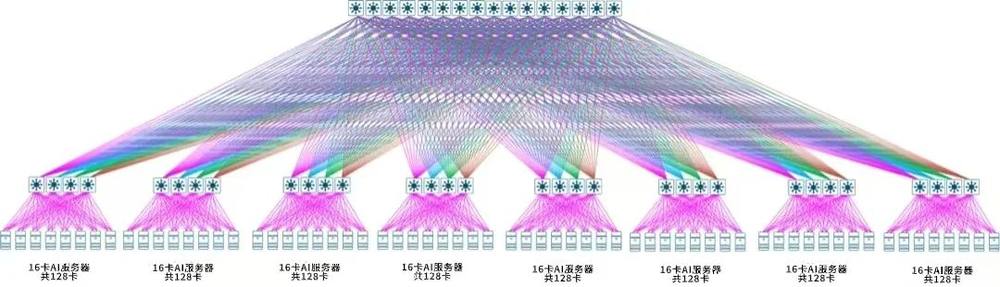
图2.华为昇腾组网架构图
为了满足AI算力训练集群对网络延迟的苛刻需求,B站技术人员联合华为工程师一起对整张网络实施了细致入微的架构设计和配置优化。AI算力网络总体按经典的Spine-Leaf两层CLOS组网设计落地,但基于大模型训练对于网络通信特点,在接入层稍微做了些变动,同时使用4台LEAF交换机连接GPU服务器的多个网口。整个网由8个POD构成,每个POD包含8台GPU节点,每台GPU配置8张400G以太网卡,每个POD可容纳128张GPU卡,从而整个集群规模可达1024张GPU卡。在SPINE层面,使用16台400G交换机来实现8个POD网络联接的对称对等。路由设计方面全网使用了EBGP路由协议,当链路出现故障时网络自动收敛。在高带宽和低延迟要求方面,全网使用RDMA技术且同时启用华为交换机特性NSLB(Network Service Load Balance,网络服务负载均衡)功能。RDMA技术无需CPU和系统内存参与的显存数据交换,能够提高通讯效率,减少系统开销;而NSLB则是华为的独有技术,可结合管理模块实现全流量的秒级感知来,继而通过高效网络编排来减少网络拥塞、丢包和锁死情况的发生,提升训练过程的可靠性,减少重新加载checkpoint的次数,以达成加快训练的效果。通过网络架构的合理设计和多种先进技术的综合应用,在训练集群内部实现400G高带宽互联、互联链路冗余、通信路径最优、Leaf上下行带宽1:1等众多先进特性。而在业务层面这些技术与特性便意味着低延迟和全网无阻塞。
在多种网络流量模型和GPU通讯库(NCCL和HCCL)验证过程中,华为昇腾整套网络方案在同Leaf下点对点网络带宽利用率超98%,延迟最低2.8微秒;“多对一”带宽利用率80%,All-to-All和AllReduce过程带宽利用率超98%。而在跨Spine测试中,华为昇腾整套网络方案仍能实现超98%的带宽利用率和最低5.6微秒的延迟;并能在“多对一”通讯中实现80%的带宽利用率和超90%的All-to-All、AllReduce带宽利用率。

图3.服务器集群布线

图4.网络集群布线
以上图3和图4为华为昇腾整套网络解决方案在B站数据中心落地示意图,在部署实施层面,华为配合B站网络技术团队完成网络规划、实施前期准备、交付前全网参数调优、HCCL通讯集参数调优和验收测试等流程,为业务上线做好充分的准备。同时为了保障整个集群的长期稳定运行,华为与B站一起对机房现场网络布线做了高标准落地,每条线缆有序布放、捆扎,降低排查链路故障等问题的难度,提升运维效率。
算网一体
让互联网+AI盛放未来
不仅B站,流量大、数据多、用户多是所有互联网业务的典型特征。而在AI业务落地的过程中,对单卡算力的锱铢必较已成过去时;借助先进网络来构建千卡、甚至万卡集群来应对业务挑战才是主流选择。因此,“算网一体、高度匹配、相互优化”也顺势成为互联网企业构建新一代基础架构时关注的重点。
对于广大行业客户而言,华为所拥有网络解决方案能力、算力解决方案能力、庞大合作伙伴体系、丰富的规划和实施经验正是构建新型基础架构、落地AI业务之所需。与此同时,华为亦在通过不断的底层技术创新和上层体验优化来实现解决方案与服务的持续精进,为互联网企业铺就通向未来的宽阔坦途。双方的相向而行也造就了华为与互联网企业联合创新、共同探索的一段段佳话。
十年前,脱胎于互联网业务逻辑的“互联网+”概念火遍全国,助力千行百业实现了业务和经营理念的跨越式升级;十年之后,互联网又成为了拥抱AI技术、引领基础架构和业务升级的先锋军。
能够与互联网产业相伴同行、共赴未来,不仅是华为的荣幸,也是ICT产业技术探索、实现价值的绝佳路径。
数智世界 一触即达” 选择华为,让您的企业轻松数智化。

时隔一年,名龙堂造&Intel粉
悦居自然山林之间,逸享边陲田园牧歌【20
对于新生代汽车消费者而言,混合动力汽车兼
随着公募行业迈向高质量发展阶段,践行数字
[土耳其,伊斯坦布尔,2024年10月3
吸引市场无数目光的中证A500指数,目前
近日,专注于打造“一脑多形”具身智能机器
去年Acnon祛痘膏销量突破200万支疫
10月31日,在武汉市委统战部指导下,武
